spring
架构
操作系统
广度优先
阿克曼
拍照
echarts
python 技巧
matlab入门案例
STM32G070RBT6
SSM就业管理
zookeeper
python爬虫
gaussdb
微机原理
Pyinstaller
ReentrantLock
数字签名伪造漏洞
跨境电商
android 糖果
nltk
2024/4/11 20:27:59
【小沐学NLP】Python使用NLTK库的入门教程
文章目录 1、简介2、安装2.1 安装nltk库2.2 安装nltk语料库 3、测试3.1 分句分词3.2 停用词过滤3.3 词干提取3.4 词形/词干还原3.5 同义词与反义词3.6 语义相关性3.7 词性标注3.8 命名实体识别3.9 Text对象3.10 文本分类3.11 其他分类器3.12 数据清洗 结语 1、简介
NLTK - 自然…

主题模型LDA教程:n-gram N元模型和nltk应用
文章目录 N-Gram 模型原理概率估计 nltk使用n-gram N-Gram 模型
N-Gram(N元模型)是自然语言处理中一个非常重要的概念。N-gram模型也是一种语言模型,是一种生成式模型。
假定文本中的每个词 w i w_{i} wi和前面 N − 1 N-1 N−1 个词有…

安装NLTK出现11004和11006错误
出现11404的错误
原因是因为访问github的ip地址出现错误 解决方案: 打开C:->Windows->System32->drivers->etc->host,
打开host文件。 在文件最后添加185.199.108.133 raw.githubusercontent.com,即可解决 可以查看raw.githubusercont…

Python anaconda nltk_data安装步骤
(1)到GitHub查找源,https://github.com/nltk/nltk_data
(2)如图所示,将packets下载下来 (3)打开jupyter,输入如下两行代码
import nltk
nltk.data.find(".")…
如何降低程序员的工资?【你中招没】
导语今天看到Yegor Bugayenko的这篇文章,觉得极为有趣,翻译过来,分享给大家。1、工资一定要保密工资必须保密,坚决不能让他们去讨论薪水,入职的时候要警告他们,或者签署保密协议禁止讨论任何薪水࿰…
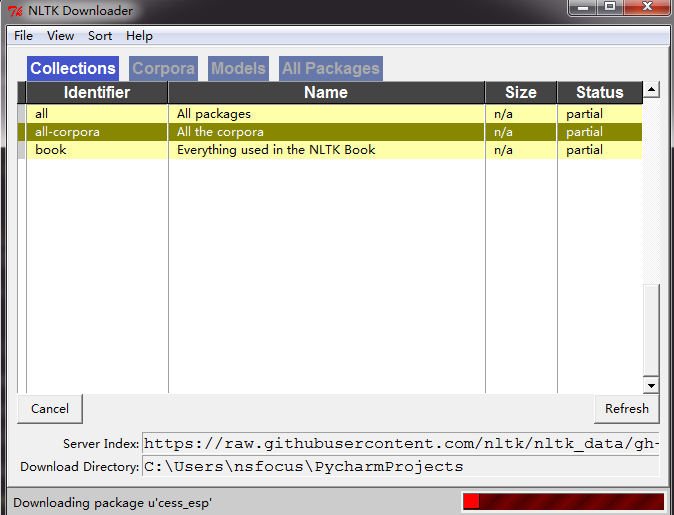
解决:NLTK包下载出错问题及NLP环境测试
Python 2.7 IDE Pycharm 5.0.3 NLTK 3.2.1 前言 需要用到自然语言处理了,安装调试过程记录一下,省的下次再找 【注意:软件安装需求:Python、NLTK、NLTK-Data必须安装,NumPy和Matplotlin推荐安装,NetworkX和…


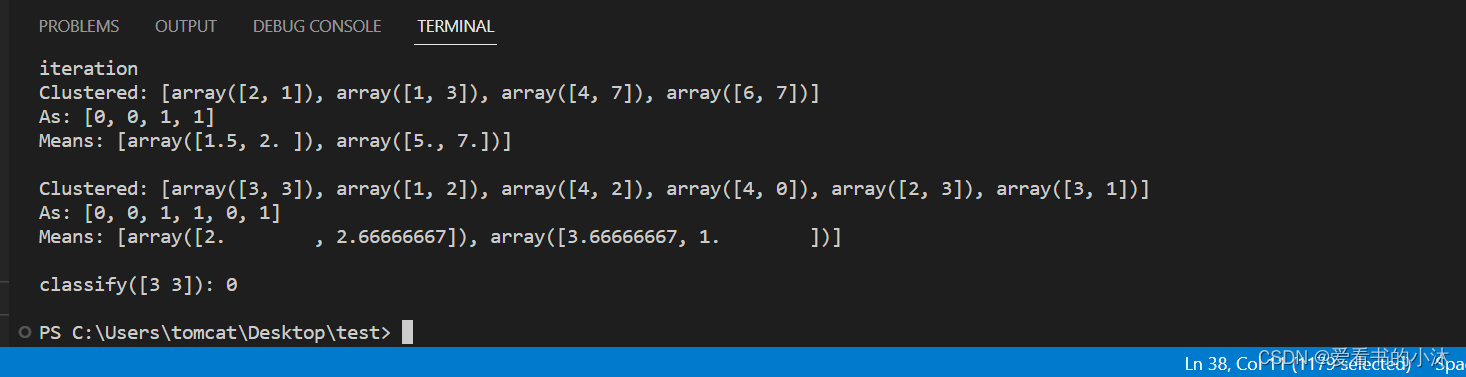
【小沐学NLP】Python实现K-Means聚类算法(nltk、sklearn)
文章目录 1、简介1.1 机器学习1.2 K 均值聚类1.2.1 聚类定义1.2.2 K-Means定义1.2.3 K-Means优缺点1.2.4 K-Means算法步骤 2、测试2.1 K-Means(Python)2.2 K-Means(Sklearn)2.2.1 例子1:数组分类2.2.2 例子2࿱…

地缘剧本杀 (六):“勇士”(原创小说连载,内含语音)
戏说大变局时代点击以下链接阅读/聆听其它章节:地缘剧本杀全集点击播放键可听语音,解放双眼本故事纯属虚构,如有雷同,纯属意外!12—勇士会后,珍妮加入了勇士。她是勇士里为数不多的女生。她觉得不管男女&am…

地缘剧本杀 (七):民意(原创小说连载,内含语音)
戏说大变局时代点击以下链接阅读/聆听其它章节:地缘剧本杀全集点击播放键可听语音,解放双眼本故事纯属虚构,如有雷同,纯属意外!14—民意加利自治邦的风暴在外邦,特别在风暴的早期、中期,也是外邦…

【词性标注】词性标注器设计
写在前面:本文用基于nltk库和Brown语料库进行演示: from nltk.corpus import brown
import nltksent brown.sents(categories news)[0] # Brown语料库中取一个句子,一会儿我们可对其进行词性标注
tagged_sents brown.tagge…

从材料到IC,人生应是一片旷野,而非轨道
编者语:今年七月份通过知乎认识退之兄,秋招的几个月,我们经常一起讨论笔试面试,互相帮助。之前就知晓退之兄是转行的,为此付出了很多努力。前几天约他来简单分享一下求职经历,希望给有意芯片行业的非科班同…
nltk download所需包
众所周知,nltk需要download一些文件才能用,但由于网络不通畅,经常下载不下来。官方链接在这里:点击官方链接
我已经帮大家下载好了必备的几个文件,资源在这里,不必担心网络问题,仅需0积分&…
自然语言处理NLP:LTP、SnowNLP、HanLP 常用NLP工具和库对比
文章目录 常见NLP任务常见NLP工具英文NLP工具中文NLP工具 常见NLP任务 Word Segmentation 分词 – Tokenization Stem extraction 词干提取 - Stemming Lexical reduction 词形还原 – Lemmatization Part of Speech Tagging 词性标注 – Parts of Speech Named entity rec…
【自然语言处理】P3 spaCy 与 NLTK(分词、词形还原与词干提取)以及 Porter 和 Snowball
目录 准备工作spaCyNLTK 文本分词spaCyNLTK 词形还原spaCyNLTK 词干提取PorterSnowball stemmers 在自然语言处理(NLP)中,文本分词是将文本拆分为单词或词组的过程,这是理解文本含义和结构的基础。Python中两个流行库——spaCy和N…
Python文本处理工具——TextRank
背景
TextRank是用与从文本中提取关键词的算法,它采用了PageRank算法,原始的论文在这里。Github地址。
这个工具使用POS( part-of-speech tagging : 词性标注 )然后抽取名词,这种方法对于关键词提取独具特色。
注意:
先安装NL…

Python数据分析:NLTK
Python数据分析:NLTK
Natural Language Toolkit nlp领域中最常用的一个Python库 开源项目 自带分类、分词等功能 强大的社区支持 语料库,语言的实际使用中真实出现过的语言材料 语料库安装 import nltk nltk.download()
语料库
nltk.corpus
分…
盛开在世界互联网大会上的智能体
撰文:康翔编辑:阿由设计:紫菜踏遍青山人未老,风景这边独好。2020年11月23日,以“数字赋能 共创未来——携手构建网络空间命运共同体”为主题的“世界互联网大会互联网发展论坛”,在浙江乌镇隆重开幕。由于全…

字节新宠火遍编程圈!内部标配超大指令集鼠标垫,粉丝每人包邮送一块!
定制指令合集鼠标垫每人一套免费包邮送到家28本高分电子书一键领取为了涨粉(bushi)我拼了……最近,我偷偷摸摸地干了一件事,且听我娓娓道来……(想免费领鼠标垫和电子书的直接拉到文末扫码即可)前不久&…

阿里新宠火遍编程圈!内部标配超大指令集鼠标垫,粉丝每人包邮送一块!
定制指令合集鼠标垫每人一套免费包邮送到家28本高分电子书一键领取为了涨粉(bushi)我拼了……最近,我偷偷摸摸地干了一件事,且听我娓娓道来……(想免费领鼠标垫和电子书的直接拉到文末扫码即可)前不久&…
【汇总】nltk相关资源包无法下载报错问题
LookupError:
**********************************************************************Resource xxx not found.Please use the NLTK Downloader to obtain the resource:>>> import nltk>>> nltk.download(xxx)
因为一些原因,下载不了nltk的相…
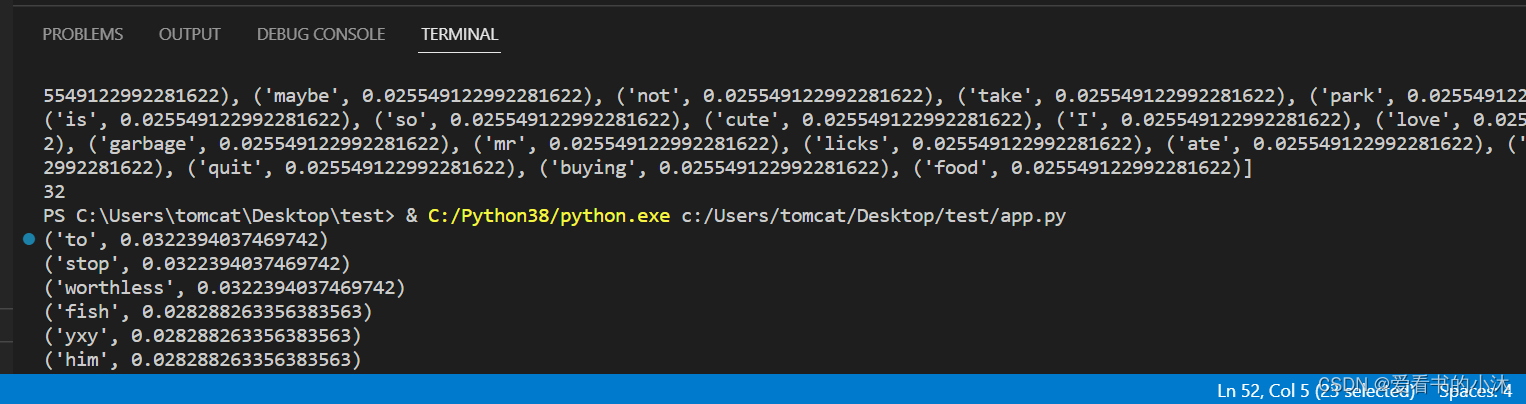
【小沐学NLP】Python实现TF-IDF算法(nltk、sklearn、jieba)
文章目录 1、简介1.1 TF1.2 IDF1.3 TF-IDF2.1 TF-IDF(sklearn)2.2 TF-IDF(nltk)2.3 TF-IDF(Jieba)2.4 TF-IDF(python) 结语 1、简介
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Fr…

nltk.download()下载数据,错误代码11004,快速本地下载数据集的方法
在下载nltk数据集的过程中,直接使用下载器会报错,原因可能是网络不稳定,需要翻墙。
import nltk
nltk.download()如果是直接下载指定的数据集,也会报错。 所以只能通过本地下载的方式,可以选择在github的官方地址下载…